Thoughtwax
Theirwork at RGS 2006
Last week I was in London for the Royal Geographical Society Annual Conference. I gave a presentation along with Dominica Williamson on a project that we’ve been collaborating on called Theirwork.
We started work on the project about a year ago, and it’s been slowly building up since (slowness being a large part of what the project is all about). It’s a mapping/locative project that we’ve been piloting with a small community of people who live around a small lake in Cornwall.
It was great to hear some opinions on the project for some actual geographers, some of whom seemed genuinely interested. Theirwork isn’t ready to be publically launched, so I’m not going to go into any great detail about it yet. For the moment, here’s a transcript of my part of the presentation, which touches on some of the design decisions taken in developing the project (bear in mind this was delivered to a room mostly comprised of geographers, so some pretty basic techie concepts are explained). Dom introduced the project and then I took over to talk about my involvement.
Full set of slides: Theirwork at the RGS (1.1MB PDF), including Dom’s workshop photos, which are much nicer and truer to the project than my boring old computer screenshots.
SUSTAINABLE SOFTWARE
So when Dom and I had our initial discussions on this project we soon realised that neither of us was very interested in treating this as a classic software building project. Or more accurately, we were interested in using the process of the project as an additional area of study.
I think Dom recognised early on in her thought process that she would need a technical person to contribute to the project, but she was also very interested in working collaboratively, and integrating a lot of outside ideas into the process. In my own work I was very much interested in examining the approach and process that someone goes through when creating software, and lending this as much importance as the final product.
Because of this we spent a lot of time discussing and planning our philosophy in relation to the process itself. One of the ideas that we developed and felt it was important to strive towards throughout the project was that of “Sustainable Software”.
For us, this approach involves taking an “open” approach to planning and building your project, even while you are in the process of doing so. I mean “open” in many senses; open to new ideas, open ended in terms of what direction the project may go in, open access to anyone who wished to get involved or branch the project in a new direction that they would like to pursue.
These ideas aren’t particularly revolutionary in the hobbyist (and increasingly the mainstream) software world where “open source” software, meaning computer programs whose source code is made available for free to anyone who may wish to look at it, adapt it to their own needs – basically do with it as they please. In fact, there is a very rich ecosystem of software development that has grown out of this area, and there are many examples of successful software project that could never have happened, or been sustainable, without this model to support it. Linux operating systems, one of the only challenges to the virtual commercial monopoly help by Microsoft with their Windows Operating System, is one example of this.
To us, sustainable software is about more than open source, though. It’s about allowing the project to naturally find it’s own path to success. To avoid being overly deterministic, even dictatorial, in our planning of a project, and instead to encourage the most worthwhile results to emerge themselves over time. The hope is that this type of approach, which would never be possible if subject to the strict restraints of commercial software development, can eventually lead of to the types of results we could never have planned if we had just sat down and tried to plan it all out on a piece of paper from day one. In any form of guerilla activity – which is what this really is, guerrilla mapmaking – the main strategic objective is to exercise your agility and turn your weaknesses to your advantage, and that what we’ve tried to do here.
| It’s also worth noting that although this model can be applied quite comfortably to software development, it’s an approach that can easily be applied to other models of production or organisation. We wanted to allow the sustainable approach to infuse all aspects of the politics and practice of our work, not just the programming part. So it’s quite adaptable to other fields of work. Although we looked to very much related fields like Green Mapping and Open Source for inspiration, we also looked further afield. Two other major influences that informed our approach come from completely different areas: the Slow Food approach, a culinary movement coming out of | taly, and Adaptive Design, an iterative approach to architecture and design were major influences. |
One final subject that I’d like to briefly touch on in relation to Sustainability in our project is that of Open Data. anyone who has ever had to deal with Ordnance Survery licensing issues will (with apologies to any OS people who may be here) may relate to this, and it’s something closely related to the field of mapping. By making your data open and free, you encourage users to get involved without fearing their work will disappear into a black hole, and your work could in turn potentially be put to use by others in some way. The more useful material that we can put into the public domain, the more we contribute to an overall encouragement of widespread engagement in these types of activities, which is ultimately what this project is all about. For the same reasons of concern for sustainability and potential for growth that led us to to adopt an Open Source Software approach, Open Data is something that we very much wanted to build into this project.
THEIRWORK SOFTWARE TOOLKIT
So, to get a little bit more specific about all of this, once we had made some philosophical or political decisions about how we wanted to go about approaching these things, we needed to decide what to actually do.
An obvious decision that needed to be made right away was to plan how to build the software. Dom already mentioned why we decided to make the project web-based, but there are a lot more specifics to be planned out. For reasons that should be obvious from the last slide, we decided not to pay for the right to use commercial mapping software. One of the next most obvious approaches when deciding to create web-based maps is to use an already-available service like Google Maps. I’m sure everyone here is familiar with Google Maps and Google Earth, they are among the most impressive and useful advances in mapping technologies in recent years.
It’s also pretty easy for anyone to create what’s become known as a Google Maps “mashup”. That is, taking an existing map, and overlaying your own set of data onto that map. As an immediate technical solution to what we wanted to do, making a Google Maps mashup seemed to be the easiest solution. So why did we eventually decide not to use Google Maps?
Well, Google’s terms and conditions stipulate that they reserve the right to, at some point in the future, place advertising on their maps. To a certain extent this concerned us, in that we couldn’t definitively say to potential contributers to the project that their work would definitely not be used for commercial means at some stage in the future. The licensing issue is a complex one, but this was enough to convince us not to use Google Maps for our project. I do believe the approach that Google has taken with Maps, to allow users to create mashups, has done incredibly great things in terms of engaging the public in the process of mapping and geography. But I think our decision here serves as a good example of where we took a principled approach to what we were doing, and made decisions in favour of longer-term thinking and sustainability.
So eventually, we decided to write our own software for representing the map on screen. Thankfully, there were some open source programming toolkits that helped greatly in doing this, and meant that we didn’t have to undertake this intimidating task from scratch. We exploited the work that others had made available, and stood on their shoulders and realise our vision in exactly the way we wanted to.
MAPPING METHODOLOGY
Of course, an additional result of not using or license a ready-made map was that we would have to create our own base map. We did this by walking around the perimeter of the lake in Cornwall that we wanted to map with a GPS unit, creating trackpoints as we went. We also took photos for reference. Other presentations today deal directly with the topic of people mapping their own places, and for us creating the map was a means to an end, so I’m not going to dwell on this for long.
However, it might be of interest to those who are wondering if this type of mapmaking is ready to break into the mainstream to note how difficult this process remains. These are the tools that we needed to map the lake that day (GPS, camera, notebook, etc.). It’s interesting to note that most of you are probably carrying more computer processing power in your pocket today that was available to almost anyone in the world twenty years ago. There are very few areas today where commercial technology, or hardware, is not yet widely available to easily create digital data. Yet the process of creating a map, or geocoding photographs or other digital media is still far from accessible to most consumers. The convergence of locative hardware, like GPS units, and other personal electronic devices has yet to happen. One has to feel that once the likes of cameras and phones become location-aware, the enormous boom in amateur photography brought about by the digital camera revolution will lead to massive amounts of locative data, and huge opportunities to present and map this data in all manner of innovative ways.
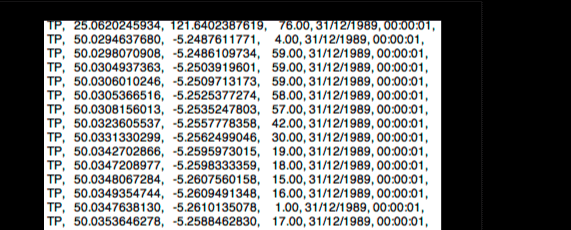
So here we see the raw longitude and latitude data collected by the GPS unit, and then that same data represented as a map. At this stage, we had created a basic map of the lake. Not a massive achievement, but when you consider the fact that this was virtually impossible to people of our means and resources just a few years ago (before the advent of GPS), it again points to the fact that we may be at the dawn of a new age of people-powered mapping.
FOLKSONOMIES
At this stage, we’ve got our interface, and we’ve got our base map. Broadly, the final area we had to tackle was how capture, process and meaningfully present the data that our user base would be adding onto our map.
Here’s where we have to ask ourselves some questions. What is a sustainable model of group data classification? Green Maps have repeatedly encountered the problem that their maps can be too narrow in subject if a strong editorial control is exerted, and too chaotic and unstructured if free reign is permitted. We wanted people to add whatever type of data they wished to the map, but we also wanted a coherent picture to emerge from the map as a whole.
Luckily, this is the type of thing that computers are quite good at; taking a lot of information and shuffling it, or slicing and dicing it, in any way we want them to. It’s also a similar problem that a lot of websites with user-generated content have experienced recently, that of trying to somehow classify all of this data without imposing structure. The aim is to somehow capture (to paraphrase a book title on this topic) the “Wisdom of Crowds”, and allow an emergent picture to develop from the teeming mass of individual actions happening within a system.
The solution here is to reject a top-down system of classification, or taxonomy, and adopt instead a system of labeling, or what has been dubbed “folksonomy”. This involves tossing out any notions of hierarchical classification, and instead allowing users to tag their data with keywords that describe it instead. A data point has many keywords pinned onto it instead of just being placed into a single category. This actually opens up the process a lot, and leads to a much more creative way of adding data. Users now have the freedom to use the map in ways that we may never have thought of in the first place, one of our major goals.

At the other end, when trying to discover or extract all of the data that I am interested in, I don’t dig down into a category to find the relevant items, but rather filter out all items by keyword. Think of it as viewing a cross-section or slice of all data, except that even within this single slice, there exists a lot more information still to be mined; many more strata of keywords that may line up, or move off in a different direction. The whole experience make for a much richer data process. This approach works great for open data in mapping, as it means that I can forget about worrying about misclassified information, or editorial control, and concentrate on extracting a meaningful signal from all this rich information.
WHAT WE ACTUALLY BUILT
So here’s what the “first draft” version turned out like. We’ve got a map, with data on it, an interface to explore it, and also a way of adding your own data to the map, live online, in your web browser.
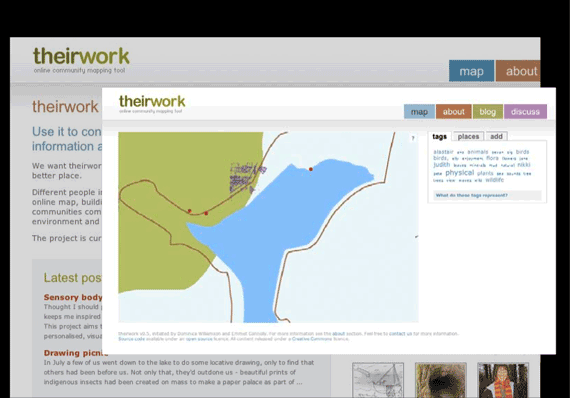
It may also be of interest to note that Dom and I lived in different countries while we worked on this, which I think in retrospect served as a positive constraint in that it encouraged us to very much think of this from an internet-based point of view. We experimented with many different forms of online communication and different media to stay in touch with each other and our workshop group, such as blog, forum, wiki, and webchat.
[back to dom]